前一回我們利用 WordNetLemmatizer 來還原詞條的衍生形體,在這之中我們引入了一項神奇武器而順利地還原詞形,今天我們就來揭開它神秘面紗!
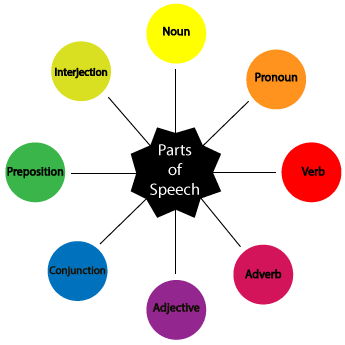
在語言學中,單詞被依照其功能以及詞形變化(inflection)分類為不同的詞性(Part of Speech, POS)。常見的詞性包含了名詞、動詞、形容詞、副詞、介係詞等等,如「 In God we trust. 」這句英文就由介係詞( in ) + 名詞( God ) + 代名詞( we )+ 動詞( trust ) 所依序構成,其句法(syntax)有別於由代名詞、動詞、介係詞、名詞依序構成的「 We trust in God. 」。我們將以詞性作為出發點,依循文法規則,進而分析文句的架構,這個過程稱為語法分析(syntactic analysis)。
在電腦科學和語言學中,語法分析(英語:syntactic analysis,也叫 parsing)是根據某種給定的形式文法對由單詞序列(如英語單詞序列)構成的輸入文字進行分析並確定其語法結構的一種過程。
原文出處:語法分析| Wikipedia
英文裡常見的詞性
當我們將句子分割成小單位,便可以利用 NLTK 工具箱中內建的函式 pos_tag() 依據詞性來標記每一個詞條:
from nltk import pos_tag
nltk.download("averaged_perceptron_tagger")
tokenised_sent = ["their", "decision", "makes", "no", "economic", "sense"]
# POS tagging
pos_tagged_sent = pos_tag(tokenised_sent)
print("POS tagged sentence:\n{}".format(pos_tagged_sent))
執行結果:
我們可以發現每個單詞的詞性都被標示出來:(關於以下詞性代號,可參照 Part-of-Speech Tags)
相信在英文課堂上老師帶領著學生分解文句結構,框選出名詞子句、形容詞子句、分詞構句等等,是大多數台灣高中生的共同記憶。今天,我們要帶領讀者重溫舊夢,將冗長的文句依照子結構進行文法拆解。
語言具有層次結構,由大高到低可依序分為:句子 → 子句 → 片語 → 單詞。
我們可以將句子的文法結構,依照層次高低描繪成分析樹(又稱具體語法樹,與抽象語法樹不同)。下圖是用來描繪句子「 Their decision makes no economic sense. 」的分析樹:
我們偶爾也會見到兩句構一致的句子: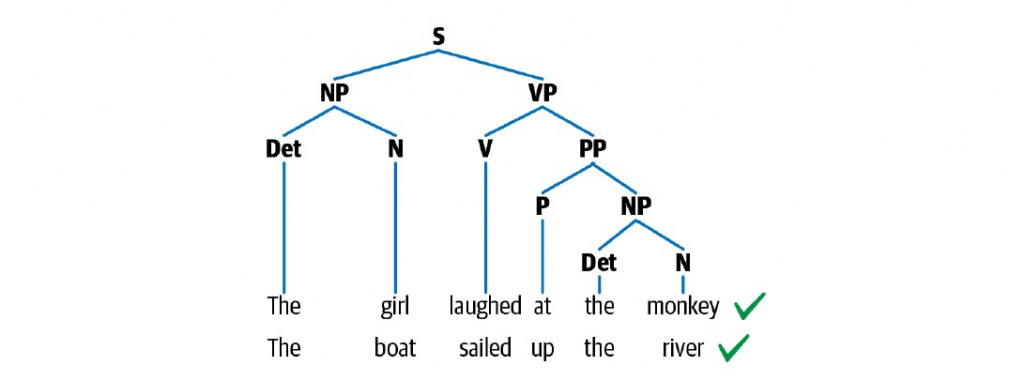
圖片來源:
Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems
句構的層次描述可以很簡單,也可以很複雜,取決於我們如何「分塊( chunking )」。我們可以依照片語或子句的文法結構指定語義組塊,透過語法剖析器( parser )逐步檢查語法(使用正則表達式比對字串),從而產生描述層次結構的分析樹。我們將示範以名詞片語以及動詞片語兩個簡單的文法結構來實踐分塊:
首先我們引入剖析器類別:
from nltk import RegexpParser
我們可利用詞性標籤( POS tags )描述位居單詞上一層的片語結構,並建立組塊:
名詞片語:
指的是具有名詞作用的單詞或詞組,如下:
# given a word tokenised sentence
tokenised_sent = ["their", "decision", "makes", "no", "economic", "sense"]
# POS tagging
pos_tagged_sent = pos_tag(tokenised_sent)
# specifying the formal grammar of an noun phrase: "grammar_name: {RegEx}"
np_chunk_grammar = "NP: {<DT>?<JJ>*<NN.?>}"
# building its parser
np_chunk_parser = RegexpParser(np_chunk_grammar)
# chunk parsing a sentence
np_chunked_sent = np_chunk_parser.parse(pos_tagged_sent)
# visualising parsing result
np_chunked_sent.draw()
執行結果:
動詞片語:
指的是由單獨一個動詞或一個動詞與助動詞(可多個)所構成的結構,如下:
動詞片語的結構較為多樣,我們姑且整理出其兩個正則表達式:
# specifying 1st formal grammar of a verb phrase
vp_chunk_grammar_1 = "VP_1: {<DT>?<JJ>*<NN.?><VB.?><RB.?>?}"
# building its parsers
vp_chunk_parser_1 = RegexpParser(vp_chunk_grammar_1)
# visualising parsing result
vp_chunk_parser_1.draw()
執行結果: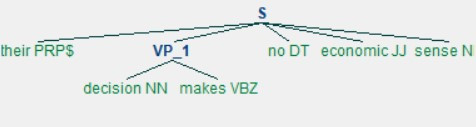
接下來試試第二種順序:
# specifying 2nd formal grammar of a verb phrase
vp_chunk_grammar_2 = "VP_2: {<VB.?><DT>?<JJ>*<NN.?><RB.?>?}"
vp_chunk_parser_2 = RegexpParser(vp_chunk_grammar_2)
# visualising parsing result
vp_chunk_parser_2.draw()
執行結果:
語義組塊刻劃了句子的文法結構,我們亦可直白地說:不一樣的組塊會長出外型不同的樹。這也讓我們得以因應不同的需求,建立不同的片語或子句分塊,客製化不一樣的分析樹,進而從多元的角度剖析字裡行間蘊藏的訊息。今天的介紹就先告一段落,明天將會介紹進階的分塊描述以及如何藉由簡短的字塊就能對文本進行資訊檢索。明天再見,各位!